
Async Backing: The way to 10x throughput lift on parachains
Parity engineer Dmitry Sinyavin explains how blockchains on Polkadot can achieve a 10x throughput increase through a combination of async backing and proof-of-validity (PoV) reclaim, enhancing transaction efficiency and scalability.
 By Polkadot•May 17, 2024
By Polkadot•May 17, 2024
Overview
Transaction throughput is something that is difficult to compare not only between different blockchains but even within a single chain. The notorious transactions-per-second (TPS) metric has a bad reputation in the Web3 world for not representing any sensible value and being easy to abuse. Still, during development, we need to evaluate our progress somehow, and that's how we do it.
This article provides a high-level explanation of how the recently calculated 10x transaction throughput increase on Polkadot parachains can be achieved. It’s worth mentioning that it isn’t one single feature that makes this possible, but a combination of both async backing and proof-of-validity (PoV) reclaim.
What Are We Measuring?
We're using the "standard TPS" (sTPS) concept, which Shawn Tabrizi excellently explained in his sub0 2024 talk. In short, we're measuring the throughput of transfer_keep_alive transactions (that is, balance transfers that do not result in account termination) from pre-funded accounts to existing accounts, one transaction per sender.
That metric is still meaningless as an absolute number, but it allows us to evaluate how throughput changes when we change the chain logic.
For this test, we're running a rococo-parachain onboarded to the rococo-local relay chain and measuring the throughput of parachain transactions.
Transactions and Their Weights
Every transaction has a weight. The weight used within the Polkadot SDK is two-dimensional, with the first dimension being the amount of computation expressed as the execution time and the second being the PoV size.
The computational weight depends on the hardware. Every piece of hardware requires a different amount of time to execute the same code, so those weights are benchmarked in advance using reference hardware.
But it's crucial to understand that those weights are worst-case scenarios. The transaction may take different execution paths. For example, if the receiving account does not exist, it must be created, which takes more time and proof size than transferring to a pre-existing account. However, when doing benchmarks in advance, we do not know what execution path a concrete transaction will take, so we always use the “heaviest” one.
Building a Block
Now, it comes to the block building. The block can accommodate a fixed amount of weight. So, when authoring a block, having the transaction pool full of transactions ready to be included, we can hit one of three limits:
- Computational weight limit. Hitting this limit means the transactions in the block consume the maximum computational resource allowed
- Block size limit. Hitting this limit means we've reached the PoV size limit, and no more transactions could fit into the block even if there's some computational resource left
- Authoring duration limit. Hitting this limit means that, although the computational resource is still available in terms of weight, in reality we consume more time for calculations than anticipated. In practice, that means that our hardware performs worse than the reference hardware used for benchmarking.
It's hard to come up with some exact numbers, as the weighting stuff is really sophisticated (parts of weights are reserved for various purposes at different stages of block building), so let's just measure.
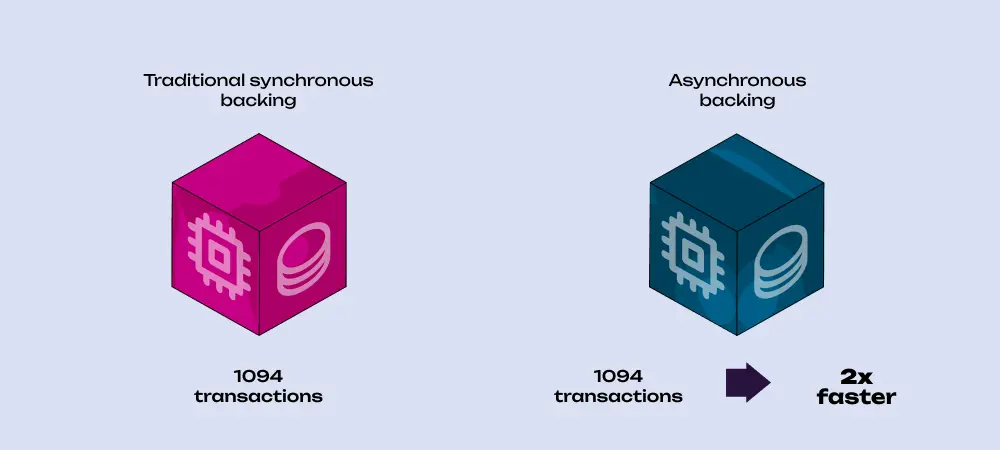
With traditional synchronous backing, we're getting 1,094 transactions in each block. We're hitting the block size limit, and plenty of computational weight remains unused even with a 0.5-second authoring duration.
Now, what will change if we introduce async backing? Sadly, not much. We have four times more computational resources, but the block size limit doesn't change, and we still hit it after 1,094 transactions are pushed into the block. However, we produce blocks twice as fast with async backing, so our throughput will double.
That's alright, but we'd expect more from sophisticated technology such as async backing, which was supposed to deliver an 8x throughput increase by itself! In addition, some technical limitations don't allow us to increase the block size to fit more transactions. So, how can we push through that limit?
POV Reclaim to the Rescue
Here, we come back to the "worst-case execution path" part. When benchmarking, we don't know exactly how much proof size a transaction will consume, and we always have to decrease block capacity by the maximum possible value. But when executing a block, we already know the actual situation. Could we report it back to the runtime and reclaim the unused proof size to fit more transactions into the block?
Yes we can - in fact, that's exactly what the PoV reclaim mechanism does. There's quite a bit to reclaim here. Every transaction is writing to the storage, thus requiring the storage proof, and the worst-case scenario we're using in our benchmarks forces us to use the full proof size, including every trie node from the account's leaf itself all the way to the root.
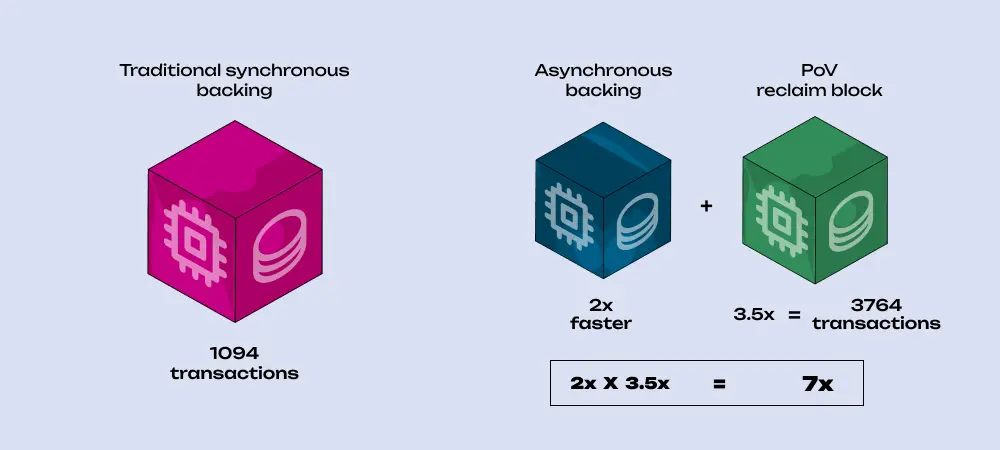
In reality, most transactions share a good part of the trie, making individual proofs much smaller. For instance, the benchmarked proof size is 3,593 bytes, which is quite close to the actual proof size of the first transaction pushed into the block. But the following ones might be as small as 250 bytes, and we'd still account for the full 3.5 Kb proof for each transaction without the PoV reclaim. Thus, with the PoV reclaim, we hit the proof size limit in the sTPS test much later.
So, with the PoV reclaim, we could fit many more transactions into the block, but the computational resource limit stops us. More than half a second is needed to process so many transactions. Here, the async backing comes in again with its two-second authoring duration. Using both technologies together, we can fit 3,764 transactions into the block, which is roughly a 3.5x increase per block, and, halving the block times, we get a rather impressive 7x! But that's not the end yet.
Playing with Constants
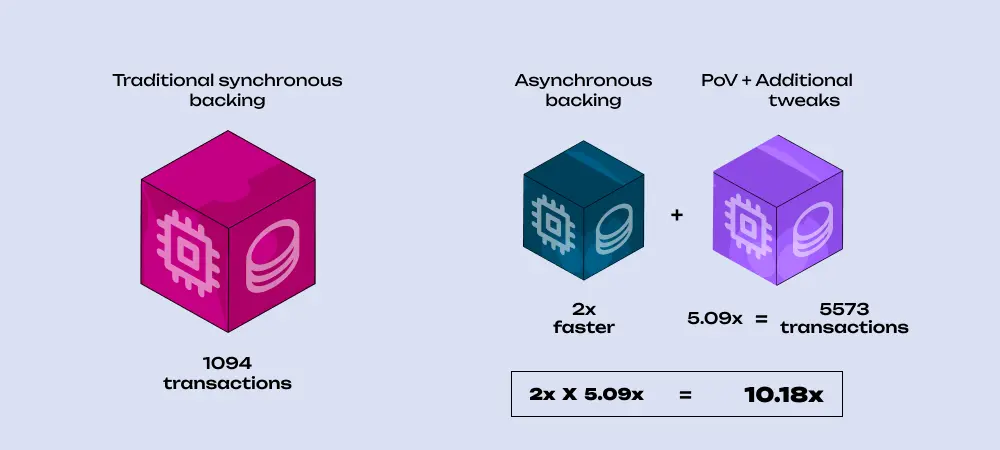
Some tweaks were needed to push the limits further. I had suggested that with async backing we get a two-second authoring duration "automagically". I confess; I lied. With the validator's backing timeout being two seconds on all the networks, we need the authoring duration to be lower than that to create a "guard zone" between those two timeouts, so the authoring duration was initially set to 1.5 seconds. But nothing can stop us from increasing the backing timeout to 2.5 seconds, and then we can use the full two seconds for authoring.
Secondly, I outlined some mysterious "reservations" in both dimensions of block weight. These are conservative estimates, accounting for the fact we do not know the exact proof sizes. But now, thanks to the PoV reclaim, we know for sure, and some of those reservations can be lifted, freeing up even more block size for the PoV.
After those tweaks, we fit 5,573 transactions into each block, which is a 5.09x increase per block, finally hitting the computational limit instead of the block size limit. After accounting for the block time halving, we get a 10.18x throughput increase.
Conclusion
Two technologies developed almost independently from each other made this result possible. It's clear that the sTPS test doesn't cover every use case, though. Networks that have most of their transactions heavily computational while producing small proofs might benefit from async backing alone. Other networks that have light transactions with large proofs might benefit from the PoV reclaim even without the async backing. But it's the synthesis of those two technologies that makes that impressive 10x throughput increase a future reality.
If You Enjoyed This Blog Article
Stay up to date on all Polkadot topics ranging from technical blogs to ecosystem initiatives and events, by following @Polkadot on X.











