
Network Stability Report: Kusama With Parachains
We’ve monitored the Kusama network for stability after the first 5 parachain auctions. We’ve sampled metrics from opt-in validators to gather the information in Prometheus and Grafana for this report.
 By Polkadot•August 17, 2021
By Polkadot•August 17, 2021
By Robert Habermeier, Polkadot Founder
We’ve monitored the Kusama network for stability after the first 5 parachain auctions. At this time, there were 6 parachains on the network.
Our interest was in 4 key areas:
- Candidate Production Stability
- Approval Voting Stats
- Network Connectivity
- Load
We’ve sampled metrics from opt-in validators to gather the information in Prometheus and Grafana as displayed in the graphs below.
Candidate Production Stability
Under ideal circumstances, in the current iteration of the protocol, each parachain produces a block for every 2 relay-chain blocks. We can determine the rate of block production for each parachain by dividing the amount of relay-chain blocks produced during the time the parachain has been online by the number of parachain blocks produced in that period of time.
The table below shows the values for the 6 current parachains as of a recent block number (#).
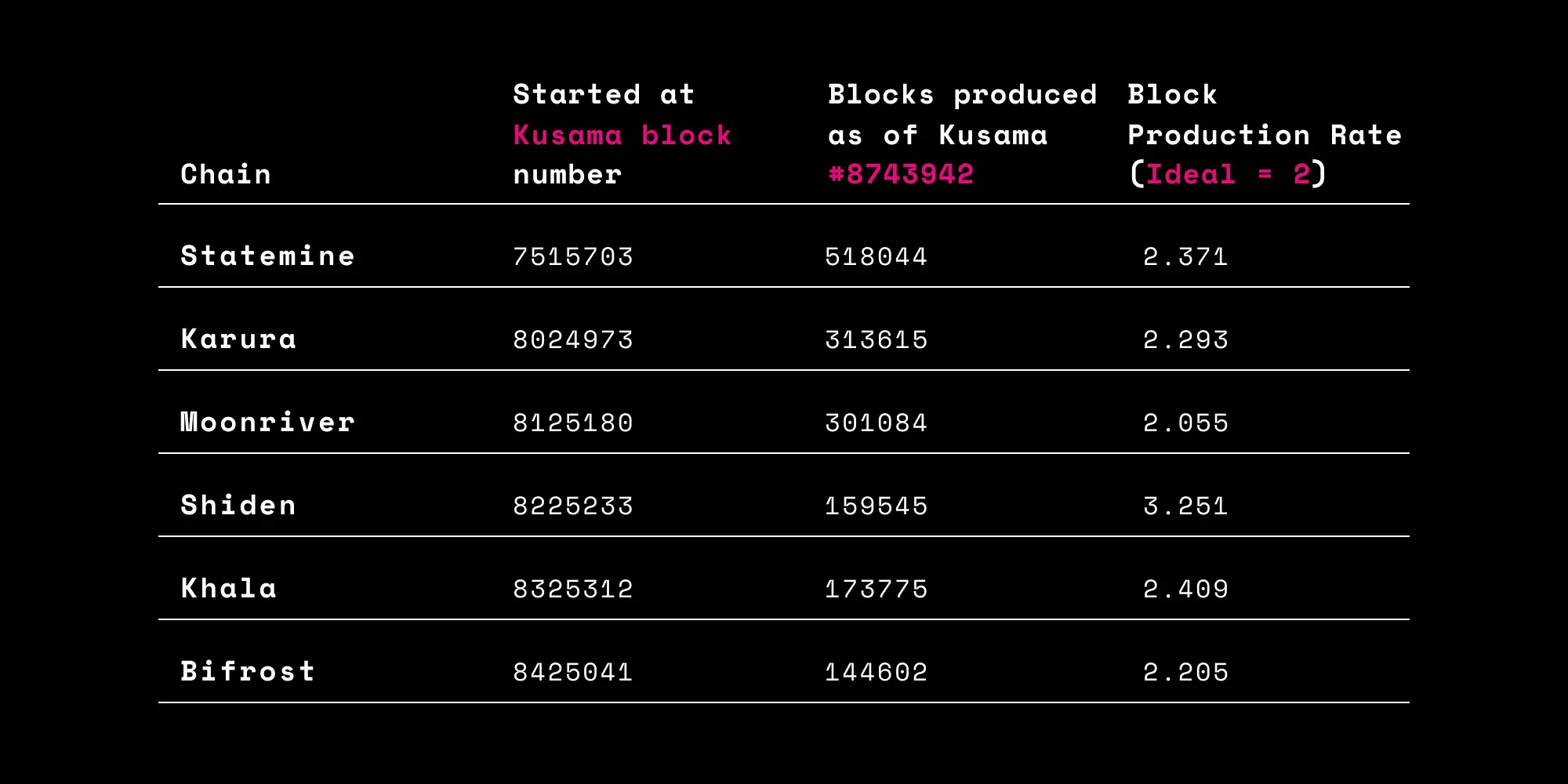
As all these parachains are secured by the same validator set and are validated by random validators — there should be no major discrepancies in the service provided by the validators to the parachains.
The effect of network noise is not worth considering at this time, as over these past days the parachains have not had enough time to be repeatedly exposed to every possible combination of backing validators. But noise certainly does not explain the large discrepancy between Shiden (and to a lesser extent, Khala) and the rest of the parachains, which mostly occupy the band between 5 and 10% off the ideal. It is worth noting that Statemine had a rocky period in the first few weeks of its launch which caused it to produce blocks only once every minute, and the current data is skewed by that initial issue.
There are two possible explanations for the discrepancy. The true reason may be one or some combination of the two:
- Heavy parachain execution or data
- Poor collator connectivity to validators
At the moment, the time window given to collators and validators to produce a parachain block is very short, which makes the system fragile and experience short delays in communication. For both issues, the long-term solution is to improve on the parachains protocol to allow a longer window for the next parachain block to be created. A short-term solution would be to position collators geographically closer to the bulk of the validator nodes. However, this creates a temporary regional centralization risk — one which would be mitigated by the long-term solution.
Approval Voting
The approval voting protocol is responsible for providing most of the security of parachains. It’s tightly integrated with the GRANDPA finality protocol. Roughly speaking, nodes are randomly selected to check the validity of parachain blocks. A certain number of nodes are required to finalize the relay chain block containing the candidate, and ‘no-shows’ who announce their intent to check but don’t follow up are automatically replaced. Disputes over validity are escalated to the entire validator set resulting in the slashing of at least one validator.
To benchmark approval voting, we can observe the following:
- GRANDPA finality lag opinions by validators
- Average ‘tranche’ of assignments by validators (ideally = 0)
- Number of assignments and approvals by validators
Finality Lag
The graph above shows on logarithmic scale, the maximum and average opinion on how many blocks should lag behind the head of the relay chain finality. Each validator has its own opinion, based on the validator’s perception of the approval status of each parachain block referenced by the relay chain.
Most of the time, this is between 2 and 5. However, it occasionally jumps up to 50. These incidents are somewhat alarming – there is a failsafe at 50 blocks which is clearly being hit very occasionally, once every few weeks.
These finality stall incidents are being investigated at the moment. We will propose a solution to governance, to resolve the issue in advance of the Polkadot parachains launch.
Average Tranche
Every validator is technically assigned to check every parachain block. The only question is when – typically only tranche 0 validators are actually enlisted to check, and later tranches only come into the picture when the tranche 0 validators fail to show up.
The graph above demonstrates that outside of the finality stall incidents, the tranches of the 50th and 95th percentile assignments are generally 0.
Assignments and Approvals
This graph demonstrates how validators’ assignments across the network are translated into their corresponding approval votes. We can see that all assignments are translated into approvals, although most of them are reported as stale. This data is inconsistent with the reported finality lag, as ‘stale’ approvals are those which become irrelevant after finality.
Almost by definition, a majority of approvals should not be stale as they are required for finality in the first place. There is a possibility that this category is being misreported or misrepresented by the node or Grafana. On Rococo, the corresponding graph shows an almost 1:1 mapping of assignments and successful approvals.
Network Connectivity
On Kusama, there are 900 validators, and every session 200 of them are randomly selected to participate in parachain consensus. Each current validator is meant to connect to the validators of the current validator set as well as the last 6 sessions.
There are a number of validators that have approximately 200 connections, and this is due to the fact that they’re part of an older validator set. Validators that are part of the current validator set should experience spikes of higher connectivity. We can see that in large part, the validators we inspected in the network are over-connected and are connected to most of the other 899 validators on the validation peer-set. This poses no problem for correctness but does present an opportunity for efficiency.
Some validators are under-connected and are not as plugged into the gossip network as they should be. Despite this, none of the validators have fewer than 100 connections, and therefore information should be gossiped to the validators, albeit over more hops.
Certain requests require point-to-point communication, and for that reason, all validators must be publicly reachable through a published node address. The node software automatically performs this function, but the node operator is responsible for ensuring that the node is reachable.
This graph shows the number of chunk requests made per second, and the number of failures of different types. The type of request here is unimportant, and the key takeaway is that ‘dial-failure’ failures (the yellow line in the lower graph) are almost exactly 10% of the number of requests made. This indicates that 10% of validators are unreachable on their published address
Load (CPU & Network)
This graph displays the CPU usage in cores by the validators. Most validators are in the 1.5-2 core utilization band. Our current recommendation is for validators to run with 4 core CPUs, so CPU utilization is within expectation.
This graph displays the CPU usage breakdown by task. The top 3 tasks dominate the CPU usage, and in descending order are the ‘libp2p-node’, ‘network-worker’, and ‘grandpa-voter’ tasks. These tasks are primarily networking-related, which indicates that optimizations in network utilization will reduce CPU utilization of the node substantially.
The majority of gossip traffic used by nodes occurs on the /polkadot/validation/1 network-protocol. This rolls up all gossip between nodes and accounts for a large portion of the network traffic. This graph shows that in general, average network bandwidth across validators is very stable at between 400-500KB/s with slightly more ‘in’ than ‘out’ bandwidth.
The majority of request/response bandwidth used by nodes is in the chunk-distribution protocol. With 200 validators and a maximum PoV size of 1MB, chunks are at peak around 15KB. At these average request/response rates, this implies a bandwidth of around 307KB/s in and 138KB/s out. However, at the moment PoVs are much, much smaller as parachains aren’t near peak transaction volume.
Recommendations
Overall, the network is running smoothly. Although average peer counts and network bandwidth appear consistent across the network, there are outlier nodes which are over-connected and experience higher levels of network bandwidth.
It appears that in the current environment, the standing recommendation of a strong 4-core CPU and 64GB Memory is more than sufficient along with a fast internet connection. Current bandwidth usage appears to be in the range of 8-16Mbps, so a typical datacenter connection of 100Mbps will be sufficient to maintain the last 5.
The only major issue is the infrequent finality stalls that are experienced by the network. These stalls are being caught by a failsafe and thus have not caused much damage, but the underlying cause is being investigated and a solution to remedy this will be proposed prior to parachains launching on Polkadot.











